Over the past few years, we have seen a significant shift in the way software is developed and deployed. We have moved beyond the ‘Just hand it to Ops and they will install it’ mentality to a more collaborative approach where developers are responsible for the entire lifecycle of their applications. This coupled with the adoption of cloud computing and their associated platforms has introduced a new set of challenges for development teams. To answer this we looked towards DevOps, a set of practices that looks to combine development and operations through a culture of collaboration and shared responsibility. But in reality, this has only shifted the burden from operations to developers, who are now responsible for managing the complexity of cloud platforms, while still delivering high-quality software.
The Developer Cognitive Load Problem
Cognitive load is the way that we describe the amount of mental effort and information required to complete a task. In terms of software development, this can be the amount of information a developer needs to keep in their head to understand and work on a particular piece of code.
With the shift in DevOps to move the responsibility of managing infrastructure towards the developers, we are seeing an increase the tasks and technologies that developers need to understand and manage.
The extra load comes in from needing to understand not just the code, but how the code builds, where the code runs, how it is monitored, how it is scaled, how it is secured, and how it is deployed. This can lead to developers spending more time managing the infrastructure than actually writing code, which can lead to burnout and a decrease in productivity.
So, what do we do about this and how can we help shift back the balance towards developers doing what they do best, writing code?
STAY TUNED
Learn more about DevOpsCon
Platform Engineering: A Strategic Response
Before we dive in too deeply, let’s first define what we mean by Platform Engineering.
Platform Engineering is the practice of empowering organisations to uplift their engineering teams by providing a platform for automating software delivery within their environment.
The key pillars of a platform are:
- Standardisation of tooling – Integrated Development Environments (IDEs), CI/CD pipelines, IaC tools, etc.
- Implementation of standardised IaC patterns – By providing standardised IaC patterns, the platform can ensure that the infrastructure is consistent and repeatable.
- Repeatable automation of deployments – By providing a standardised deployment pipeline, the platform can ensure that deployments are repeatable and reliable.
- Monitoring and Observability – Making monitoring and observability an integral part of the platform and open to not just the platform team but the development teams as well.
- Integration with Security tooling and frameworks – Secure by default should be the aim, integrating security tooling and frameworks into the platform can help ensure that the applications are secure.
Platform engineering seeks to support all these pillars to enable the development teams to focus on what they do best while keeping the operational environments manageable, secure and scalable.
So, now that we have defined the goals of Platform Engineering, how do we go about actually delivering these goals?
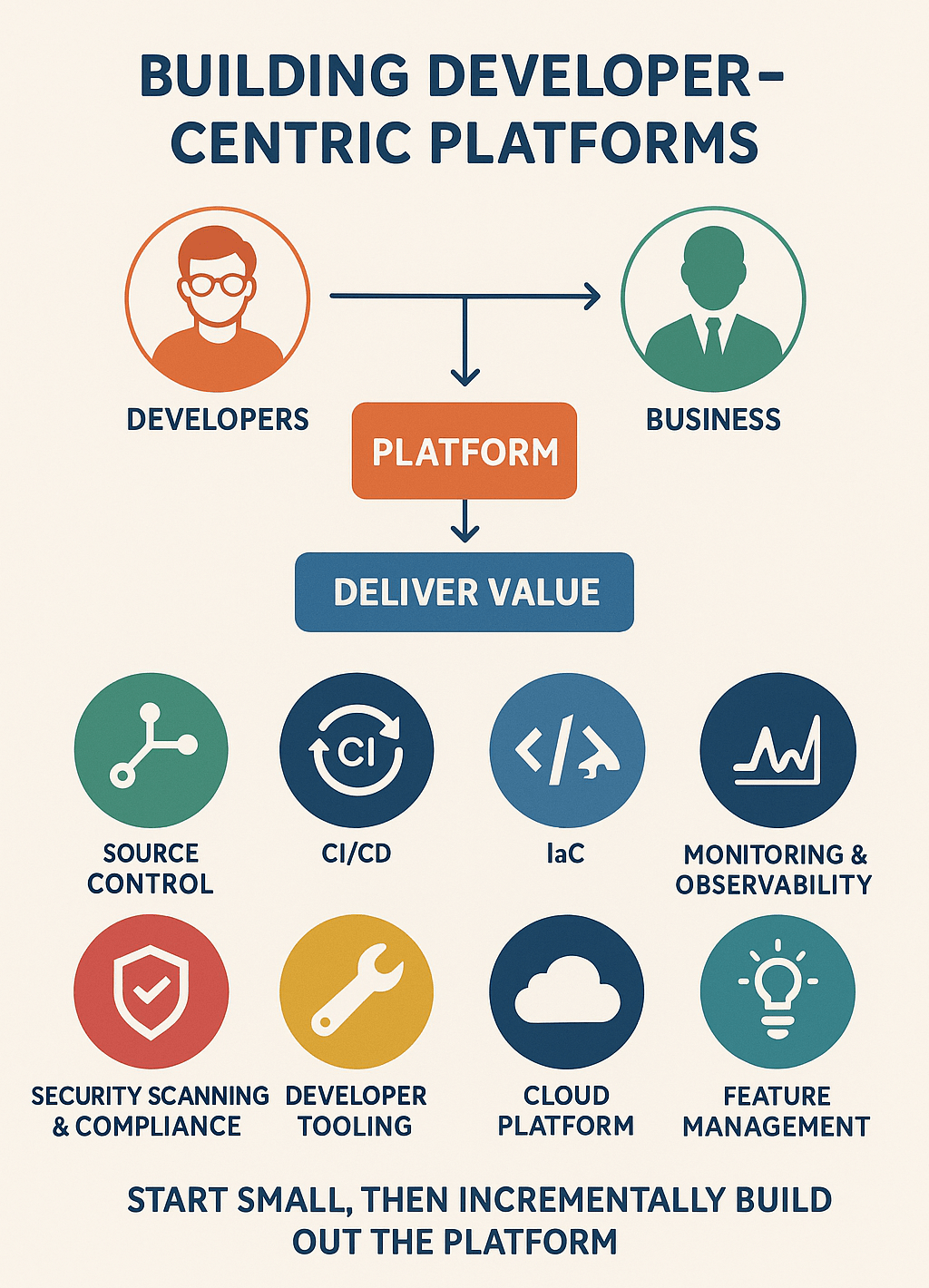
Building Developer-Centric Platforms
As a starting point, we need to understand the needs of the developers and the business they are providing value to. The goal of Platform Engineering is to focus on the developers as the primary customer and the platform as the means to deliver value to the business.
So, this means we need to ensure that the platform is scoped to the technologies and tools that the developers are using, and that the platform is designed to be easy to use and understand.
But this can get complicated quickly, with a large array of systems and tools to try and integrate into a single platform. As an example, let’s have a look at what might be required for a fairly simple web development team:
-
- Source Control
- Continuous Integration and Deployment (CI/CD)
- Infrastructure as Code (IaC)
- Monitoring and Observability
- Security Scanning and Compliance
- Developer tooling
- Cloud Platform
- Feature Management
Kubernetes Training (German only)
Entdecke die Kubernetes Trainings für Einsteiger und Fortgeschrittene mit DevOps-Profi Erkan Yanar
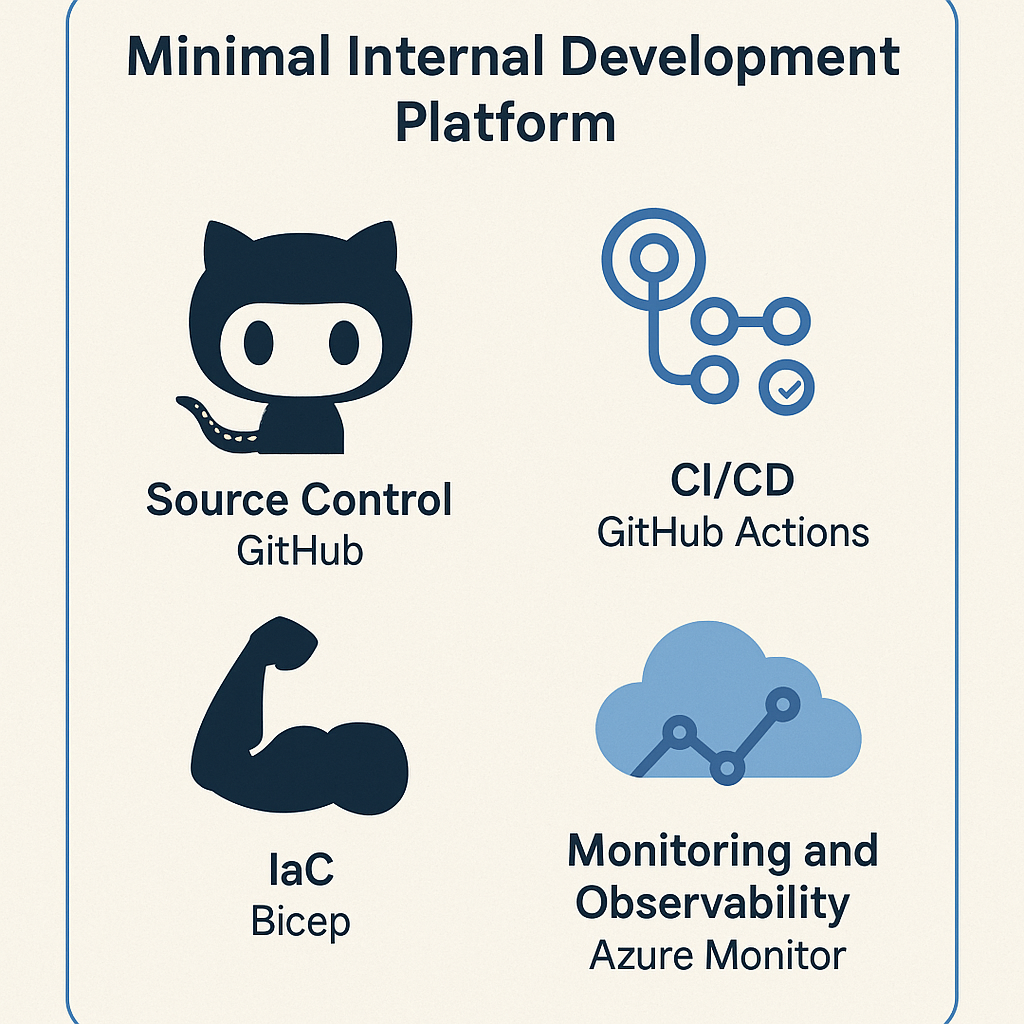
Minimal Internal Development Platform
So, let’s start out with an example minimal internal development platform.
- Source Control: GitHub
- CI/CD: GitHub Actions
- IaC: Bicep
- Monitoring and Observability: Azure Monitor
With these tools, you can start to build your platform.
Starting with source control and CI/CD, you can create template repositories that developers can use to get started quickly. Include bare bones CI/CD pipelines that give guidelines to developers but still give them the flexibility to customise.
For IaC again, start with a simple template, maybe only for one team to start with, work with them to understand how they use it and what can be stored in a central repository vs needing to be customized per team.
Monitoring and Observability can be a bit harder, but focus on the simple things first, like making sure the apps are up, monitoring the load and response times, and then getting both the platform team and development teams to work together to consume the data and make decisions.
Developer Experience on the Platform
So, now that we have a basic platform in place, how does that work towards improving the Developer Experience? At its core, the platform should focus on reducing the time to first deployment.
This means providing developers with template repositories that include pre-configured CI/CD pipelines, infrastructure definitions, and monitoring setup. Instead of spending days setting up their development environment, developers can be deploying their first application within hours.
From there, we focus on reducing cognitive load through self-service capabilities. This means developers can provision resources and deploy applications without needing to understand the complexities of Kubernetes configurations or cloud infrastructure specifics.
For example, a developer should be able to deploy a new web application by simply pushing their code to a repository, with the platform handling the creation of the necessary cloud resources, security configurations, and deployment pipelines.
The platform should also provide rapid feedback loops to developers. This includes not just basic application metrics like response times and error rates, but also deployment success rates, security scan results, and cost implications of their infrastructure choices.
Making this information readily available through dashboards or integrated into their development tools helps developers make informed decisions quickly.
To measure the platform’s impact on developer productivity, we need to look at concrete metrics:
- Performance metrics (deployment frequency, success rates)
- Team efficiency metrics (time spent on tasks)
- User satisfaction metrics (surveys, support tickets)
We should regularly review these metrics with development teams to identify pain points and areas for improvement.
Are developers still struggling with certain aspects of the platform? Are there common requests that could be automated? This continuous feedback loop is crucial for platform evolution.
Remember, not one size will fit all teams or organizations. Start small with a core set of features, work collaboratively with development teams to understand their needs, and build out the platform incrementally based on real usage patterns and feedback.
So What Does This Mean For DevOps Teams?
Throughout this article we have been talking about Platform Engineering and Developer Experience, but what does this mean for the DevOps teams?
Essentially, DevOps was never meant to be a team, but a set of practices and principles that should be adopted by all teams.
The engineering roles that have been brought together under DevOps such as Site Reliability Engineers (SRE) and Cloud Engineers will still be needed, but their focus will be on managing and maintaining the infrastructure that the platform is built on.
As I see it, the scope of the teams are as follows:
Cloud Engineers – Responsible for the underlying cloud infrastructure and services that the platform is built on, this includes the networking and security that serves not just the platform but the entire business.
SREs – Responsible for the reliability and availability of the platform, this includes monitoring and alerting, incident response, and capacity planning. They are the first line responders, able to quickly have a grasp of the situations and empowered to reach out to the required teams to resolve the issue.
Platform Engineers – Responsible for the platform itself, this includes the CI/CD pipelines, IaC templates, monitoring and observability, and security tooling. They are the ones that work with the development teams to understand their needs and build out the platform to meet those needs.
While they all might still be brought together under the name of a DevOps team, I think it is important that we recognize the different roles and responsibilities that these engineering disciplines have.
Conclusion and Future Outlook
While we have been leveraging and using DevOps for a while I think it is now time we look to its next evolution.
Platform Engineering lets us focus on providing efficiency and value to the development teams, which in turn provides value to the business.
We should also be looking at platforms as ways to help us measure the developer experience of our teams, by providing metrics and feedback loops we can start to understand where the platform is working and where it is not.
Overall, just like with DevOps there will be lots of ways to look at Platform Engineering, but the key is to keep the developers at the centre of the conversation and ensure that the platform is providing value to them.
So, I encourage you all to start thinking about platforms, even from just the simplest templates to how you could build out an internal development platform, but remember, start small and iterate often.
Platform Engineering & Developer Cognitive Load FAQ
What is the developer cognitive load problem?
The developer cognitive load refers to the mental effort and information developers must juggle—code, builds, infrastructure, monitoring, scaling, security, and deployment. DevOps practices often shifted infrastructure complexity onto developers, which can lead to burnout and reduced productivity.
What is Platform Engineering?
Platform Engineering is the practice of creating and maintaining a self-service platform that automates software delivery. It includes standardized tooling, Infrastructure as Code patterns, CI/CD pipelines, observability, and security integrations.
How does Platform Engineering reduce cognitive load?
A platform streamlines workflows by providing template repositories, pre-configured CI/CD pipelines, infrastructure and monitoring templates, and self-service deployment tools. This reduces the need for developers to understand every detail of the infrastructure stack.
What are the key pillars of a developer-centric platform?
- Standardized tooling (IDEs, CI/CD, IaC)
- Repeatable automation of deployments
- Built-in monitoring and observability
- Secure-by-default integrations
How should organizations start building an internal development platform?
Start with a minimal viable stack (e.g., GitHub, GitHub Actions, IaC templates, and monitoring). Provide template repositories to help developers deploy their first applications quickly. Expand incrementally based on developer feedback.
How does Platform Engineering improve developer experience?
It shortens time-to-first-deployment, automates infrastructure setup, enables resource provisioning with a push of a button, and provides rapid feedback loops via integrated dashboards. This frees developers to focus more on coding rather than operations.
How can teams measure the success of Platform Engineering?
- Deployment frequency and success rates
- Time spent on tasks before vs. after platform adoption
- Developer satisfaction metrics (e.g., surveys, support tickets)
How does Platform Engineering impact DevOps and related roles?
Platform Engineering doesn’t replace DevOps—it complements it. Cloud Engineers continue managing infrastructure, SREs focus on reliability, and Platform Engineers build and evolve the platform while collaborating closely with developers.
What is the main takeaway from this approach?
The next evolution after DevOps is treating platforms as products. Start small, iterate often, keep developers at the center, and incorporate feedback continuously to ensure the platform delivers real value.